

Platypus: A New Leader in Large Language Models Fine-Tuning
It's mainly about the data that is fed to the LLMs


TL;DR: The research paper "Platypus: Quick, Cheap, and Powerful Refinement of LLMs" introduces Platypus, a family of fine-tuned and merged Large Language Models (LLMs) that achieve top performance on HuggingFace's Open LLM Leaderboard. Platypus uses the Open-Platypus dataset, a curated collection of public text datasets focused on STEM and logic, to fine-tune the LLaMa 2 model, a 70B parameter LLM released by Meta. The fine-tuning process is efficient, with a 13B Platypus model trainable on a single A100 GPU using 15k questions in just 5 hours. The results showcase the effectiveness and efficiency of the Platypus approach, making it a powerful tool for researchers and developers in the field of NLP.
Large Language Models (LLMs) have the potential to revolutionize various applications, from chatbots to content generation. However, fine-tuning these models for optimal performance remains a challenge. A recent research paper, "Platypus: Quick, Cheap, and Powerful Refinement of LLMs," introduces a novel approach to address this issue.
Platypus: A New Approach to LLMs
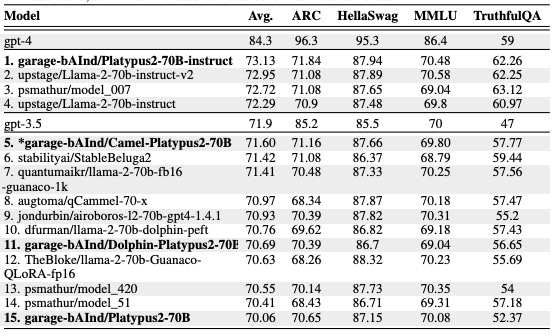
Platypus is a family of fine-tuned and merged LLMs that have achieved remarkable success. In fact, Platypus currently holds first place in HuggingFace's Open LLM Leaderboard, showcasing its superior performance. One of the most impressive aspects of Platypus is its efficiency. A 13B Platypus model can be trained on a single A100 GPU using 15k questions in just 5 hours. This quick and cost-effective training process makes Platypus an attractive option for researchers and developers working with LLMs.
The Open-Platypus Dataset
The research paper introduces the Open-Platypus dataset, a curated collection of public text datasets specifically designed for fine-tuning LLMs. The dataset focuses on improving LLMs' knowledge in STEM and logic, two areas that are often challenging for language models. Open-Platypus is composed of 11 open-source datasets, providing a diverse and high-quality training set for LLMs.
The main advantage of Open-Platypus is its size and quality. Despite being a small-scale dataset, it allows for a very strong performance with short and cheap fine-tuning time and cost. This makes it an invaluable resource for researchers and developers looking to enhance the performance of their LLMs.
The LLaMa 2 Model
Meta, formerly known as Facebook, has been at the forefront of LLM development with its LLaMa models. These models are known for their computational efficiency during inference, making them well-suited for a wide range of NLP tasks. Recently, Meta released LLaMa 2, a model with a staggering 70B parameters. This model serves as the base for the Platypus family of LLMs.
Fine-Tuning with Open-Platypus
The research paper details the approach to fine-tuning the LLaMa 2 model using the Open-Platypus dataset. The fine-tuning process employs Low-Rank Approximation (LoRA) and the Parameter-Efficient Fine-Tuning library, ensuring optimal performance. The fine-tuning process focuses on depth in specific areas, diversity of input prompts, and keeping the training set small. This approach aims to maximize the precision and relevance of the model's outputs, making it more useful for real-world applications.
Dataset Curation and Cleaning
Open-Platypus consists of 11 open-source datasets. The backbone of Open-Platypus is a modified version of the MATH dataset, supplemented with expanded step-by-step solutions from PRM800K. The dataset includes long-form answers to multiple-choice questions. This approach provides more detailed explanations and context for the model during training.
Duplicate questions were removed from the dataset in two ways. First, word-to-word duplicates were removed. Then, questions with an 80% cosine similarity were removed. Among the duplicates, the question-answer pair that was the most verbose was kept, as longer answers likely translate to more detailed explanations.

Results
The results of the research paper underscore the effectiveness of the Platypus approach to fine-tuning LLMs. Utilizing the Open-Platypus dataset and the LLaMa 2 model, the researchers achieved remarkable performance improvements, as evidenced by Platypus's top position on HuggingFace's Open LLM Leaderboard. This accomplishment highlights the model's superior performance compared to other LLMs and showcases the quality of the Open-Platypus dataset.
Additionally, the research paper emphasizes the efficiency of the Platypus approach. A 13B Platypus model can be trained on a single A100 GPU using 15k questions in just 5 hours. This quick and cost-effective training process distinguishes Platypus from other LLMs, making it an attractive option for researchers and developers working with limited resources.
Conclusion
Platypus represents a significant step forward in the field of LLMs. Its efficient training process, coupled with the high-quality Open-Platypus dataset, makes it a powerful tool for researchers and developers. As LLMs continue to play a more prominent role in various applications, the contributions of Platypus will likely have a lasting impact on future research and developments in NLP.
Stay Ahead in the world of LLMs! 🚀 Loved our article on Platypus and LLMs? Subscribe to our newsletter for more cutting-edge research insights.